While converting word to pdf using groupdocs-conversion 24.6 facing an issue
" Reading order is not correct for the page as header is read out first and then directly the footer section is getting read out and then the main content"
I’m sorry for the delayed response. I have created the issue in our internal bug-tracker. The issue ID is CONVERSIONJAVA-2497. We’ll take a look and update you.
At the moment we do not have any updates for this issue. It requires detailed investigation. We’ll let you know in case of any new information.
hi @vladimir.litvinchik may you please help fix this issue as its been pending over a month now, thanks
Unfortunately, I can’t reproduce this issue.
When reviewing the sample file’s with-headers-and-footers.pdf (17.6 KB) structure I can see that header and footer were rendered as artifacts see header-and-footer.png (84.4 KB) and therefore it is not readable by JAWS see contents visible to screen reader file-in-pac.png (78.4 KB).
May you please attach the file that you’re trying to read to reproduce this issue?
Please note that there are no specific header/footer tags defined for PDF/UA documents. Possibly they should be represented as a paragraphs.
Thank you for sharing the sample file. I can confirm that I can reproduce the issues that you’ve described in Chrome and Edge browsers on Windows.
I have the latest version of Chrome and JAWS 2024 installed. And here are the results that’ve got:
As you can see the reading quality is better in Adobe Acrobat.
After analyzing the GroupDocs.Conversion for Java output PDF document structure I have created tagged PDF header footer test.pdf (87.2 KB) using Microsoft Word. I did make sure to create tagged PDF for acesibility:
- docx-document-accesibility-check.png (119.1 KB)
- docx-document-save-as-accesible-pdf.png (115.8 KB)
Then I have tested PDF created by Microsoft Word with JAWS in Chrome and Adobe Acrobat and got the same results as with the file created by GroupDocs.Conversion for Java.
It seems to be an issue with Google Chrome of with JAWS since JAWS features list Chrome as a supported software:
- Works with Microsoft Office, Google Docs, Chrome, Edge, Firefox, and much more
Unfortunately, I can’t confirm that the issue you’re experiencing is related to GroupDocs.Conversion for Java.
Have you tried contacting JAWS support with this issue?
Thank you for reply here @vladimir.litvinchik . Can you also confirm on issue
“Reading order of each tabular section is not correct and reading the entire row section at once as the entire row is identified as one single element. The table is not identified as table / cells are not associated with the table header cells”
This is browser related issue?
We are facing “Link doesn’t have valid content.” If we are trying add any link in document. This will also be browser related?
Can you also confirm on issue
“Reading order of each tabular section is not correct and reading the entire row section at once as the entire row is identified as one single element. The table is not identified as table / cells are not associated with the table header cells”
This is browser related issue?
Yes, according to the results I’ve got (see my comment) it it highly likely that the issue is related to the browser PDF rendering engine. The tests with Adobe Acrobat shows that the content is properly tagged.
Please check this two videos:
I have noticed that Adobe Acrobat recognized that this is a link while in Chrome it being read as a text.
I was using this sample file link_test.docx (12.2 KB) that I’ve created in Microsoft Word and then converted it to PDF using GroupDocs.Conversion - link_test.docx.pdf (17.9 KB).
Can you please clarify what issue you’re experiencing when reading PDF file with links?
Hi @vladimir.litvinchik In above recording can you please confirm why header is not read out first and footer is not read in end. Only we are reading body in header footer test.pdf
have tested with voice over in mac and getting same result
I have checked the header footer test.pdf file and found that header and footer are represented as artifacts in PDF document see the screenshot from PAC:
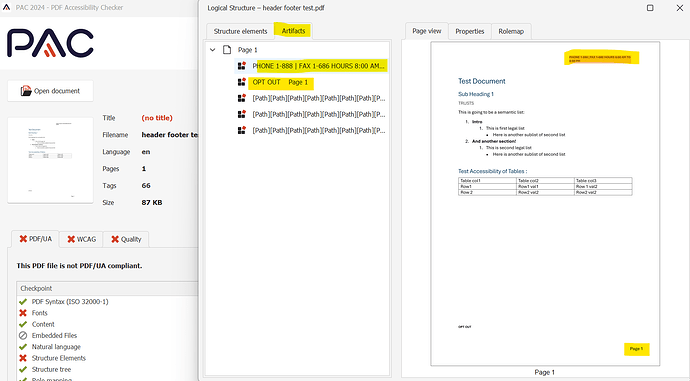
Screen readers typically skip the elements that are tagged as artifacts. Artifacts are elements like page numbers or repeated text that are not meant to be read aloud.
Hi @vladimir.litvinchik Thank you for reply. I tried reading via adobe acrobat and voice over in mac but I was not seeing heading related tags over there. Can you please confirm on this ? Also was able to read header in windows chrome using nvda. If this is considered as artifact then screen reader should not read in windows. What the difference in mac and windows can you please help us understand?
Were you able to read table here in windows?
Possibly it happens because different screen readers process artifacts in it’s own way. Have you checked the documentation for NVDA?
May you please clarify which document and which tool to open the PDF file you’re referring to?
@vladimir.litvinchik I have not checked the documentation of NVDA.
I am referring to the header footer test.pdf document only. In windows while using chrome nvda was not able to identify table whereas in mac voice over was able to identify the table